Date:
Location:
Presentation by Miranda Lupion, Harvard University
View the slides, listen to the audio, or read a text transcription of the audio of this presentation.
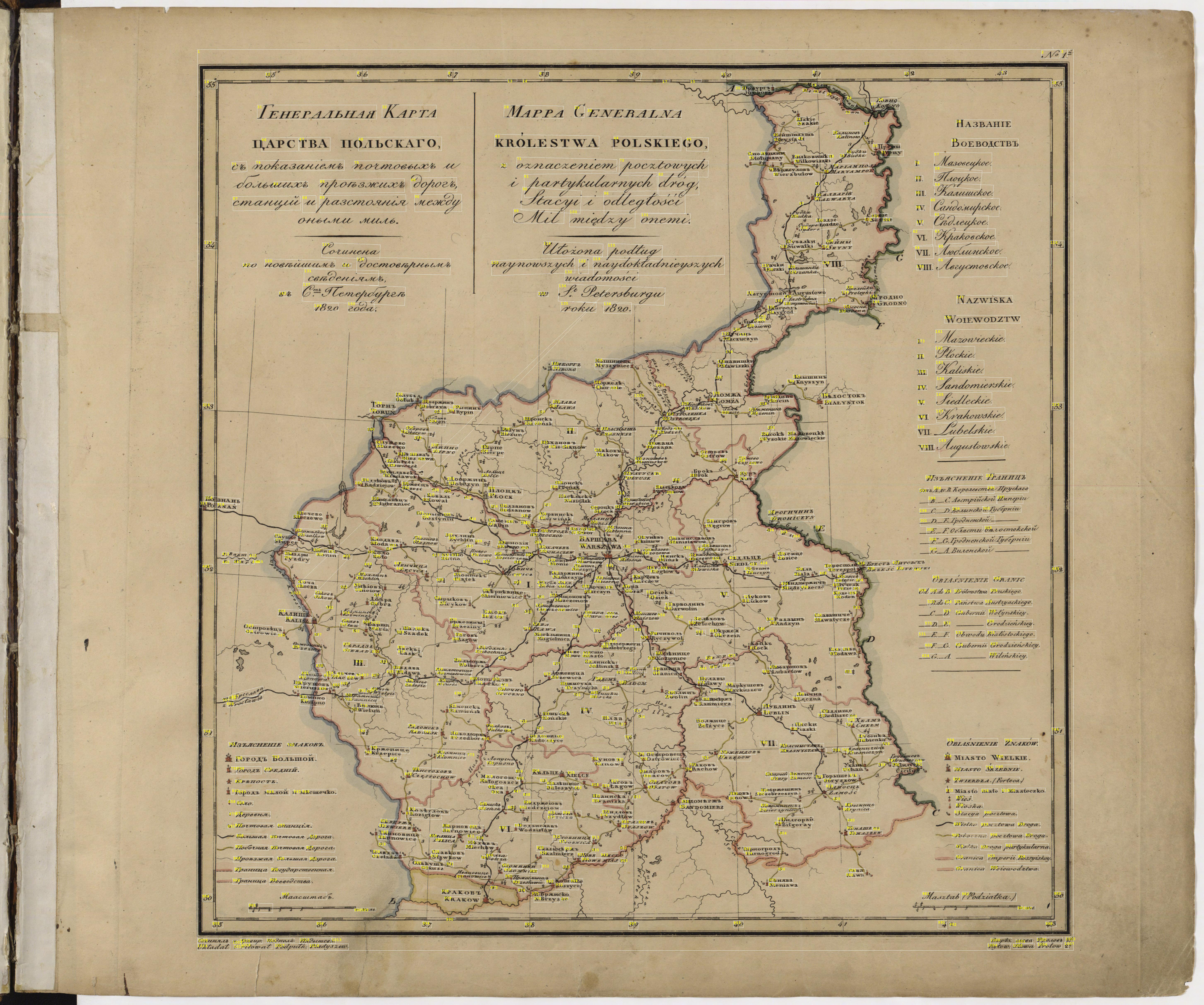
Abstract: My research explores the potential to partially or fully automate settlement name extraction from historical maps using Google’s out-of-the-box optical character recognition (OCR) algorithm. A prerequisite to meaningful cartographic analysis, manual placename extraction is time-consuming, expensive, and mundane. Implemented through an API, Google’s Cloud Vision algorithm may offer a partially automated alternative to this process. To test the pre-packaged algorithms accuracy, I use the API to perform feature detection on four sheets from the 1827 Geographical Atlas of the Russian Empire. I then assess the accuracy of each of the roughly 4,000 returned text units and record other details as well. Through exploratory data analysis of the results, I consider how language, font choice, and settlement placement impacts accuracy. Based on my results, I discuss areas where a trained rather than pre-packaged algorithm might boost OCR accuracy. I also consider potential pre- and post-processing procedures that, when applied to data, may improve outcomes. My findings have implications for geospatial digital humanities projects.
Speaker Bio: Miranda Lupion is a graduate student at Harvard University in the Regional Studies: Russia, Eastern Europe, and Central Asia M.A. program and an Innovation Fellow with the Davis Center's Imperiia Project. Her research interests include Internet technology regulation and use in Russia, Russian foreign policy, GIS, digital humanities, OCR, and automation.
Lunch will be served.