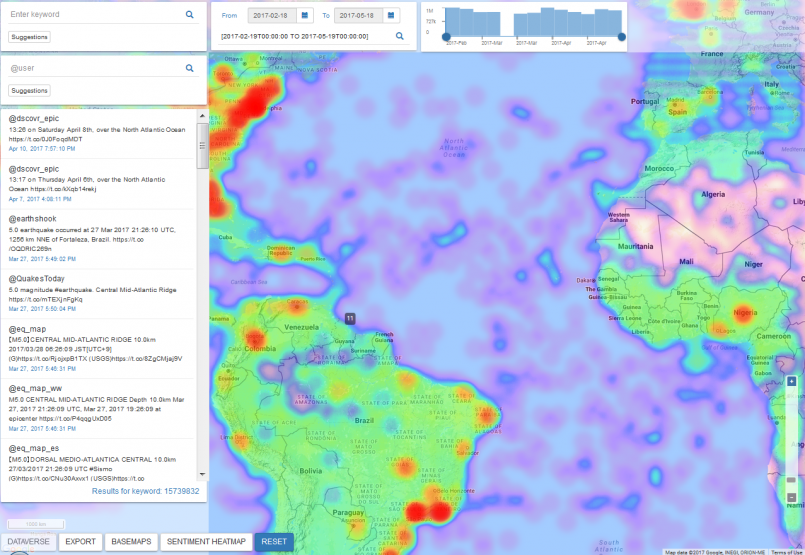
The Billion Object Platform (BOP)
With funding from the Sloan Foundation and Harvard Dataverse, Ben Lewis, Devika Kakkar, Merce Crosas, and David Smiley developed a prototype, open source, spatio-temporal visualization platform dubbed "the BOP" (Billion Object Platform). The first goal of the BOP was to provide the Dataverse platform with an API-accessible big data exploration tool which could support streaming data. The more general goal was to lower barriers for scholars who wish to access large, streaming, spatio-temporal datasets by addressing a basic limitation of geospatial platforms when it comes to interactive visualization of more than a couple million features.
To support the interactive visualization of billions of features, the CGA, with David Smiley, developed new capabilities for the widely used Solr and Lucene libraries in the form of spatial and temporal faceting.
The first instance of the BOP was loaded with the latest billion geo-tweets, and fed a real-time stream of about 1 million tweets per day. The geo-tweets were enriched with sentiment and census/admin boundary codes on their way into the system. The system was open source and was hosted on Massachusetts Open Cloud (MOC), an OpenStack environment with all components deployed in Docker, and orchestrated by Kontena. Here is an overview of the BOP architecture, which is built on a stack consisting of Apache Lucene, Solr, Kafka, Zookeeper, Swagger, scikit-learn, OpenLayers, and AngularJS.
The CGA has been harvesting geo-tweets since 2012 and has developed an archive which contains many billions of tweets. More information on the archive is available here Harvard CGA Geotweet Archive . If you are interested in learning more about this archive please contact us.
Investigators: Gary King, Merce Crosas, Ben Lewis